

Code 42, la société derrière CrashPlan a décidé d'abandonner complètement les utilisateurs à domicile CrashPlan Shutters Cloud Backup pour les utilisateurs à domicile CrashPlan Shutters Cloud Backup pour les utilisateurs Home Code42, la société derrière CrashPlan, a annoncé qu'il est en train d'abandonner les utilisateurs à domicile. CrashPlan for Home est en train de disparaître, Code42 se concentrant entièrement sur les entreprises et les entreprises. Lire la suite . Leurs prix super compétitifs ont fait de leur solution de sauvegarde une telle tentation pour les personnes ayant des besoins de sauvegarde importants. Alors que leur échec à tenir leurs promesses a pu semer des graines de méfiance, il existe d'autres fournisseurs de cloud. Mais quel fournisseur faites-vous confiance avec vos archives de memes?
Amazon Web Services (AWS) est actuellement le leader mondial en matière de cloud computing. La courbe d'apprentissage pour AWS peut sembler abrupte, mais en réalité, c'est simple. Voyons comment tirer parti de la première plate-forme cloud au monde.
Solution de stockage simple
La solution de stockage simple, communément appelée S3, est le monstre d'Amazon d'une solution de stockage. Certaines entreprises notables qui utilisent S3 comprennent Tumblr, Netflix, SmugMug et bien sûr, Amazon.com. Si votre mâchoire est toujours attachée à votre visage, AWS garantit la durabilité de 99, 99999999999 pour son option standard et une taille de fichier maximale (de n'importe quel fichier) de cinq téraoctets (5 To). S3 est un magasin d'objets, ce qui signifie qu'il n'est pas conçu pour l'installation et l'exécution d'un système d'exploitation, mais qu'il est parfaitement adapté aux sauvegardes.
Les niveaux et les prix
De loin, c'est la partie la plus compliquée de S3. Les prix varient d'une région à l'autre, et notre exemple utilise les prix actuels pour la région des États-Unis (Virginie du Nord). Jetez un oeil à cette table:

S3 est composé de quatre classes de stockage. La norme est évidemment l'option standard. Raccourci Accès est généralement moins cher pour stocker vos données, mais il est plus coûteux d'obtenir vos données dans et hors de. La redondance réduite est généralement utilisée pour les données que vous pouvez régénérer en cas de perte, comme les vignettes d'image par exemple. Glacier est utilisé pour le stockage d'archives car il est le moins cher à stocker. Cependant, il faudra entre trois à cinq heures avant de pouvoir récupérer un fichier de Glacier. Avec le glacier ou le stockage à froid, vous obtenez des coûts par gigaoctet réduits, mais des coûts d'utilisation accrus. Cela rend le stockage à froid mieux adapté à l'archivage et à la reprise après sinistre. Les entreprises profitent généralement d'une combinaison de toutes les classes pour réduire davantage les coûts.
Le meilleur de chaque catégorie est marqué en bleu. La durabilité est la probabilité que votre fichier soit perdu. Bar Reduced Redundancy, Amazon devra subir une perte catastrophique dans deux centres de données avant que vos données soient perdues. Fondamentalement, AWS stockera vos données dans plusieurs installations avec toutes les classes à l'exception de la classe de redondance réduite. La disponibilité est telle qu'il est peu probable qu'il y ait des temps d'arrêt. Le reste est plus facile à démontrer au moyen d'un exemple.
Exemple d'utilisation
Notre cas d'utilisation est le suivant.
Je veux stocker dix fichiers sur S3 Standard avec une taille totale d'un gigaoctet (1 Go). Le téléchargement des fichiers ou Put entraînera la demande au coût de 0, 005 $ et 0, 039 $ pour le stockage total. Cela signifie que le premier mois, vous devrez payer un total d'environ 4, 5 cents (0, 044 $) et un peu moins de 4 cents (0, 039 $) pour le stationnement de vos données par la suite.
Pourquoi y a-t-il une structure de prix aussi complexe? C'est parce que c'est payant pour ce que vous utilisez. Vous ne payez jamais pour tout ce que vous n'utilisez pas. Si vous pensez à une entreprise de grande envergure, cela offre tous les avantages d'avoir une solution de stockage de classe mondiale, tout en maintenant les coûts à un minimum absolu. Amazon fournit également une calculatrice mensuelle simple que vous pouvez trouver ici, de sorte que vous pouvez projeter vos dépenses mensuelles. Heureusement, ils offrent également un niveau gratuit, que vous pouvez vous inscrire ici, de sorte que vous pouvez tester leurs services jusqu'à 12 mois. Comme avec tout ce qui est nouveau, une fois que vous commencez à l'utiliser, le plus confortable et compréhensible devient.
La console
Le niveau gratuit d'AWS vous permet d'essayer tous leurs services, dans une certaine mesure, pendant une année complète. Dans le niveau libre, S3 vous offre 5 Go de stockage, 20 000 gains et 2 000 puts. Cela devrait permettre une grande marge de manœuvre pour tester AWS et décider si cela correspond à vos besoins. L'inscription à AWS vous guide à travers quelques étapes. Vous aurez besoin d'une carte de crédit ou de débit valide et d'un téléphone à des fins de vérification. Une fois la console de gestion lancée, vous serez accueilli dans le tableau de bord AWS.
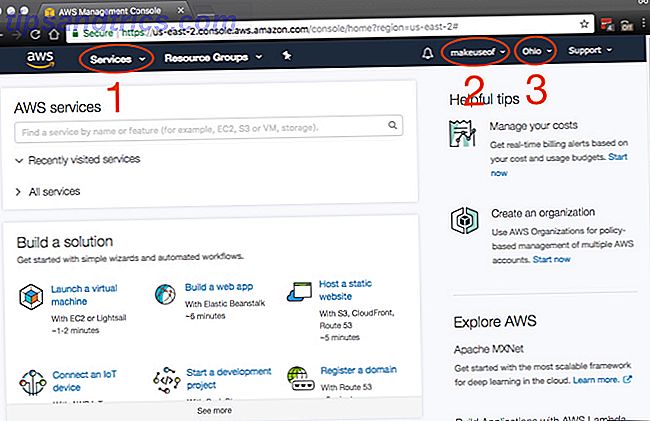
En un coup d'œil, il peut sembler qu'il y a énormément de choses à prendre, et c'est tout simplement parce qu'il y en a. Les principaux éléments auxquels vous accéderez, qui sont annotés dans la capture d'écran, sont:
- Services: Surprise, surprise c'est ici que vous trouverez tous les services AWS.
- Compte: Pour accéder à votre profil et à votre facturation.
- Région: C'est la région AWS dans laquelle vous travaillez.
Parce que vous voulez la latence la plus faible entre votre (vos) ordinateur (s) et AWS, choisissez une région qui vous est la plus proche. Certaines régions ne disposent pas de tous les services AWS, mais elles sont mises en place de façon continue. Heureusement pour nous, S3 est disponible dans toutes les régions!
Sécurité S3
Avant de continuer, le premier travail consiste à sécuriser votre compte. Cliquez sur Services> Sécurité, identité et conformité> IAM . Au cours du processus, nous allons également accorder les autorisations nécessaires à votre ordinateur, afin que vous puissiez sauvegarder et restaurer en toute sécurité.
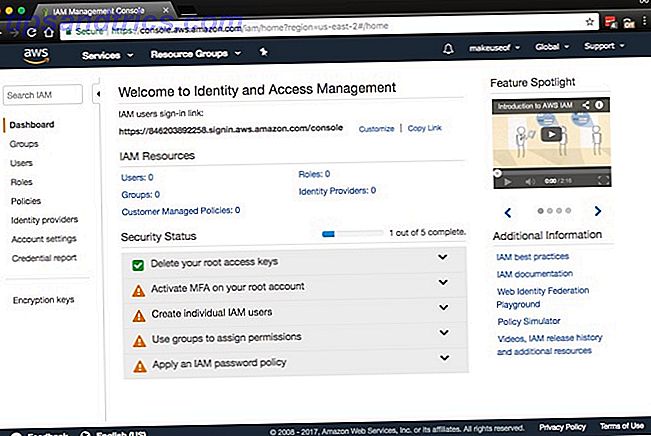
C'est un processus simple en cinq étapes. Vous remarquerez à partir de la capture d'écran que MFA peut être activé sur votre compte. Bien que l'authentification multifactorielle (MFA), également connu sous le nom d'authentification à deux facteurs (2FA) Comment sécuriser Linux Ubuntu avec l'authentification à deux facteurs Comment sécuriser Linux Ubuntu avec l'authentification à deux facteurs Vous voulez une couche de sécurité supplémentaire sur votre connexion Linux? Grâce à Google Authenticator, il est possible d'ajouter une authentification à deux facteurs à votre PC Ubuntu (et à d'autres systèmes d'exploitation Linux). Lire la suite, n'est pas nécessaire, il est fortement recommandé. En un mot, il nécessite une combinaison de votre nom d'utilisateur et mot de passe, avec un code sur votre appareil mobile. Vous pouvez obtenir un périphérique MFA physique compatible ou utiliser une application telle que Google Authenticator. Rendez-vous sur l'App Store ou sur le Play Store pour télécharger l'application Google Authenticator.
Utilisation de l'authentification multifacteur en option
Développez Activer MFA sur votre compte root et cliquez sur Gérer MFA . Assurez-vous qu'un périphérique MFA virtuel est sélectionné et cliquez sur Next Step .
Ouvrez Google Authenticator sur votre appareil et scannez le code-barres affiché à l'écran. Tapez le code d'autorisation dans la zone Code d'autorisation 1 et attendez que le code soit actualisé dans Google Authenticator. Il faut environ 30 secondes pour que le code suivant s'affiche. Saisissez le nouveau code dans la zone Code d'autorisation 2 de Google Authenticator. Maintenant, cliquez sur le bouton Activer le MFA virtuel . Une fois que vous avez actualisé votre écran, Activer MFA aura la coche verte.

Vous devez maintenant activer MFA sur votre compte et associer Google Authenticator à AWS. La prochaine fois que vous vous connecterez à AWS Console, vous devrez taper votre nom d'utilisateur et votre mot de passe normalement. AWS vous demandera alors un code MFA. Cela sera obtenu à partir de l'application Google Authenticator comme vous l'avez fait à l'étape précédente.
Groupes et autorisations
Il est temps de décider du niveau d'accès de votre ordinateur à AWS. Le moyen le plus simple et le plus sûr de le faire sera de créer un groupe et un utilisateur pour l'ordinateur que vous souhaitez sauvegarder. Accordez alors l'accès ou ajoutez une permission pour que ce groupe accède seulement à S3. Cette approche présente de nombreux avantages. Les informations d'identification fournies à ce groupe sont limitées à S3 et ne peuvent pas être utilisées pour accéder à d'autres services AWS. En outre, dans le cas malheureux où vos informations d'identification sont divulguées, vous devez simplement supprimer l'accès au groupe et votre compte AWS sera sécurisé.
Il est en fait plus logique de créer le groupe en premier. Pour ce faire, développez Créer des utilisateurs IAM individuels, puis cliquez sur Gérer les utilisateurs . Cliquez sur Groupes dans le panneau de gauche, puis sur Créer un nouveau groupe . Choisissez un nom pour votre groupe et cliquez sur Next Step . Maintenant, nous allons joindre la permission ou la politique pour ce groupe. Comme vous voulez seulement que ce groupe ait accès à S3, filtrez la liste en tapant S3 dans le filtre. Assurez-vous que AmazonS3FullAccess est sélectionné et cliquez sur Next Step, enfin sur Create Group .

Créer un utilisateur
Tout ce que vous devez faire maintenant est de créer un utilisateur et l'ajouter au groupe que vous avez créé. Sélectionnez Utilisateurs dans le panneau de gauche, puis cliquez sur Ajouter un utilisateur . Choisissez un nom d'utilisateur, sous Type d'accès, assurez-vous que l' accès par programmation est sélectionné et cliquez sur Suivant: Autorisations . Sur la page suivante, sélectionnez le groupe que vous avez créé et cliquez sur Suivant: Révision . AWS confirmera que vous ajoutez cet utilisateur au groupe sélectionné et confirmera les autorisations accordées. Cliquez sur Créer un utilisateur pour passer à la page suivante.
Vous verrez maintenant un ID de clé d'accès et une clé d'accès secrète . Ceux-ci sont auto-générés et ne sont affichés qu'une seule fois. Vous pouvez soit les copier et les coller dans un emplacement sécurisé, soit cliquer sur Télécharger .csv qui téléchargera une feuille de calcul contenant ces informations. C'est l'équivalent du nom d'utilisateur et du mot de passe que votre ordinateur utilisera pour accéder à S3.
Il est important de noter que vous devriez les traiter avec le plus haut niveau de sécurité. Si vous perdez votre clé d'accès secrète, il n'y a aucun moyen de la récupérer. Vous devrez revenir à la console AWS et en générer une nouvelle.

Votre premier seau
Le temps est venu de créer une place pour vos données. S3 a des magasins appelés seaux. Chaque nom de compartiment doit être globalement unique, ce qui signifie que lorsque vous créez un compartiment, vous êtes le seul sur la planète avec ce nom de compartiment. Chaque compartiment peut avoir son propre ensemble de règles de configuration. Vous pouvez activer la gestion des versions sur les compartiments afin de conserver les copies des fichiers que vous mettez à jour afin de pouvoir revenir aux versions précédentes des fichiers. Il existe également des options pour la réplication entre régions, ce qui vous permet de sauvegarder vos données dans une autre région d'un autre pays.
Vous pouvez accéder à S3 en accédant à Services> Stockage> S3 . La création d'un compartiment est aussi simple que de cliquer sur le bouton Créer un compartiment . Une fois que vous avez choisi un nom unique au monde (en minuscules uniquement), choisissez une région dans laquelle vous souhaitez que votre compartiment se loge. Cliquez sur le bouton Créer pour obtenir votre premier compartiment.

La ligne de commande est la vie
Si la ligne de commande est votre arme de choix 4 façons de vous enseigner les commandes de terminal sous Linux 4 façons de vous enseigner les commandes de terminal sous Linux Si vous voulez devenir un véritable maître Linux, il est bon d'avoir quelques connaissances terminales. Voici des méthodes que vous pouvez utiliser pour commencer à vous enseigner. En savoir plus, vous pouvez accéder à votre nouveau compartiment S3 en utilisant s3cmd que vous pouvez télécharger ici. Après avoir choisi la dernière version, téléchargez l'archive zip dans le dossier de votre choix. La dernière version actuelle est 2.0.0 que vous utiliserez dans notre exemple. Pour décompresser et installer s3cmd, ouvrez une fenêtre de terminal et tapez:
sudo apt install python-setuptools unzip s3cmd-2.0.0 cd s3cmd-2.0.0 sudo python setup.py install s3cmd est maintenant installé sur votre système et est prêt à être configuré et lié à votre compte AWS. Assurez-vous d'avoir votre ID de clé d'accès et votre clé d' accès secrète à portée de main lorsque vous avez créé votre utilisateur. Commencez par taper:
s3cmd --configure Vous allez maintenant être invité à entrer quelques détails. Tout d'abord, vous serez promu pour entrer votre identifiant de clé d'accès suivi de votre clé d'accès secrète. Tous les autres paramètres peuvent être conservés par défaut en appuyant simplement sur la touche Entrée, à l'exception du paramètre Chiffrement . Vous pouvez choisir un mot de passe ici afin que les données envoyées dans et hors de S3 sont cryptées. Cela empêchera un homme dans l'attaque centrale Cinq outils de chiffrement en ligne pour protéger votre vie privée Cinq outils de chiffrement en ligne pour protéger votre vie privée En savoir plus, ou quelqu'un d'intercepter votre trafic Internet.
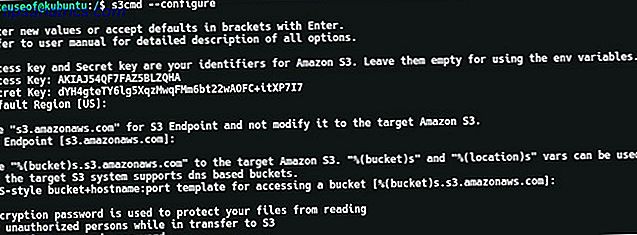
À la fin du processus de configuration, s3cmd effectuera un test pour s'assurer que tous les paramètres fonctionnent et que vous pouvez vous connecter à votre compte AWS. Lorsque cela est fait, vous serez en mesure de taper quelques commandes comme:
s3cmd ls Cela va lister tous les seaux dans votre compte S3. Comme le montre la capture d'écran ci-dessous, le seau que vous avez créé est visible!

Synchroniser en utilisant la ligne de commande
La commande de synchronisation pour s3cmd est extrêmement polyvalente. C'est très similaire à la façon dont vous copieriez normalement un fichier sous Linux, et ressemble un peu à ceci:
s3cmd sync [LOCAL PATH] [REMOTE PATH] [PARAMETERS] Testez son utilisation avec une simple synchronisation. Commencez par créer deux fichiers texte à l'aide de la commande touch, puis utilisez la commande sync pour envoyer les fichiers que vous venez de créer dans le compartiment créé précédemment. Rafraîchissez le seau S3; vous remarquerez que les fichiers ont bien été envoyés à S3! Assurez-vous de remplacer le chemin d'accès local par le chemin d'accès local sur votre ordinateur, ainsi que de modifier le chemin d'accès distant à votre nom de compartiment. Pour accomplir ce type:
touch file-1.txt touch file-2.txt s3cmd sync ~/Backup s3://makeuseof-backup 
La commande sync, comme mentionné, commence par vérifier et comparer les deux répertoires. Si un fichier n'existe pas dans S3, il le téléchargera. Plus encore, si un fichier existe, il vérifiera s'il a été mis à jour avant de le copier sur S3. Si vous souhaitez également supprimer les fichiers que vous avez supprimés localement, vous pouvez exécuter la commande avec le paramètre -delete-removed . Testez cela en supprimant d'abord l'un des fichiers texte que nous avons créés, suivi de la commande sync avec le paramètre supplémentaire. Si vous actualisez ensuite votre compartiment S3, le fichier supprimé a été supprimé de S3! Pour essayer ceci, tapez:
rm file-1.txt s3cmd sync ~/Backup s3://makeuseof-backup --delete-removed 
En un coup d'œil, vous pouvez voir à quel point cette méthode est convaincante. Si vous souhaitez sauvegarder quelque chose sur votre compte AWS, vous pouvez ajouter la commande sync à un travail cron Comment planifier des tâches sous Linux avec Cron et Crontab Comment planifier des tâches sous Linux avec Cron et Crontab La possibilité d'automatiser des tâches est l'une de celles technologies futuristes qui est déjà là. Chaque utilisateur de Linux peut bénéficier de la planification du système et des tâches de l'utilisateur, grâce à cron, un service d'arrière-plan facile à utiliser. Lisez la suite et sauvegardez automatiquement votre ordinateur sur S3.
L'alternative GUI
Si la ligne de commande n'est pas votre truc, il existe une alternative à l'interface utilisateur graphique (GUI) à s3cmd: Cloud Explorer. Bien qu'il ne dispose pas d'une interface très moderne, il possède des fonctionnalités intéressantes. Ironiquement, la méthode la plus simple pour mettre la main sur la dernière version est via la ligne de commande. Une fois que vous avez ouvert une fenêtre de terminal avec un dossier dans lequel vous souhaitez l'installer, tapez:
sudo apt -y install How to Use APT and Say Goodbye to APT-GET in Debian and Ubuntu How to Use APT and Say Goodbye to APT-GET in Debian and Ubuntu Linux is in a state of permanent evolution; major changes are sometimes easily missed. While some enhancements can be surprising, some simply make sense: check out these apt-get changes and see what you think. Read More openjdk-8-headless ant git git clone https://github.com/rusher81572/cloudExplorer.git cd cloudExplorer ant cd dist java -jar CloudExplorer.jar Lorsque l'interface se lance, certains champs obligatoires devraient déjà vous sembler familiers. Pour charger votre compte AWS, entrez votre clé d'accès, votre clé secrète et donnez un nom à votre compte, puis cliquez sur Enregistrer .
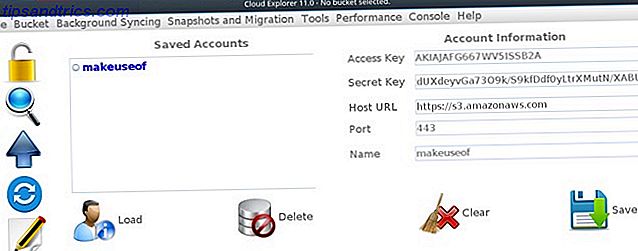
Vous pouvez maintenant cliquer sur votre profil enregistré et accéder à votre compartiment.
Explorer l'explorateur
Jetez un coup d'œil à l'interface, vous verrez ce qui suit:
- Connectez - Out
- Explorer et rechercher
- Télécharger des fichiers
- Synchronisation
- Éditeur de texte
- Un panneau pour une liste de vos seaux
- Un panneau pour naviguer dans un compartiment sélectionné
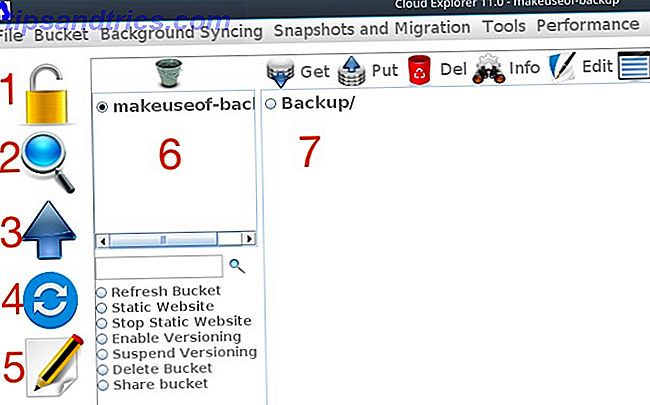
La configuration des capacités de synchronisation de Cloud Explorer est similaire à s3cmd. Tout d'abord, créez un fichier qui n'existe pas dans le compartiment S3. Ensuite, cliquez sur le bouton Sync dans Cloud Explorer et naviguez jusqu'au dossier que vous souhaitez synchroniser avec S3. Cliquer sur To S3 vérifiera les différences entre le dossier sur votre ordinateur local et le dossier avec S3 et téléchargera les différences qu'il trouve.
Lorsque vous actualisez le compartiment S3 dans le navigateur, vous remarquerez que le nouveau fichier a été envoyé à S3. Malheureusement, la fonction de synchronisation de Cloud Explorer ne prend pas en charge les fichiers que vous avez supprimés sur votre ordinateur local. Donc, si vous supprimez un fichier localement, il restera toujours dans S3. C'est quelque chose à garder à l'esprit.

Les utilisateurs à domicile peuvent utiliser le stockage en nuage axé sur les entreprises
Bien qu'AWS soit une solution conçue pour que les entreprises tirent parti du cloud, il n'y a aucune raison pour que les utilisateurs à domicile ne participent pas à l'action. L'utilisation de la plate-forme cloud leader au monde présente de nombreux avantages. Vous n'avez jamais à vous préoccuper de la mise à niveau du matériel ou du paiement de tout ce que vous n'utilisez pas. Un autre fait intéressant est que AWS a plus de parts de marché que les 10 autres fournisseurs combinés. C'est une indication de la distance qui les attend. La configuration d'AWS en tant que solution de sauvegarde nécessite:
- Créer un compte.
- Sécurisation de votre compte avec MFA.
- Création d'un groupe et attribution de permissions au groupe.
- Ajouter un utilisateur au groupe
- Création de votre premier seau
- Utiliser la ligne de commande pour synchroniser avec S3.
- Une alternative graphique pour S3.
Utilisez-vous actuellement AWS pour quelque chose? Quel fournisseur de sauvegarde cloud utilisez-vous actuellement? Quelles caractéristiques recherchez-vous lorsque vous choisissez un fournisseur de sauvegarde? Faites-nous savoir dans les commentaires ci-dessous!